Super Ninja Privacy Techniques for Web App Developers
If I keep my documents on Google Docs, my mail on Yahoo Mail, my bookmarks on del.icio.us, and my address book on .Mac, is there any point in talking about the privacy of my data any more? Should I just accept that using web-hosted applications means that privacy doesn’t exist?
Many new applications do a great job of making it easy and free for you to post your information online. In a lot of cases, your data is combined with other people’s data, to pull helpful or interesting relationships out of aggregate data (“People who bought this book also bought….”). Your photos on your hard drive are not as useful as your photos on Flickr, where others can comment on them, find them via tags, share them, and make them into photo-related products.
Obviously, though, this shift has many implications for privacy, and it is worth wondering what the future of privacy is for web application users. A security breach on one of the most popular hosted web applications could easily reveal private information about thousands or even millions of the site’s users. An employee of one of the largest providers could access information about the site’s users without anyone knowing. How should a user of these applications think about these risks?
Right now, most application providers either don’t talk about these risks or simply ask users to trust that they have their best interests in mind; and as far as we know, the companies providing these applications do in fact make great efforts to respect the privacy of their users. As users, though, the “trust us” proposition does not offer much in the way of reliability of certainty. We essentially must rely on the harm that a large-scale privacy breach would cause the provider as counter-incentive against allowing one to occur.
As developers of Wesabe, and online personal finance community, we think about these questions a great deal. We believe that there is a significant benefit to consumers in anonymously combining their financial data online, since this allows us to produce an aggregate view of where consumers find the best values (sort of like a reverse FICO score — a value rating for businesses). However, this project asks our users for a lot of trust. We decided from the outset that, as a startup without the name recognition of a Google or Yahoo, and simply as people interested in providing privacy and security to our users, that we should come up with as many approaches as possible that would help us protect Wesabe users’ privacy.
Many of these techniques are generally applicable. While there is a fair amount of information online for individuals who want to protect their own privacy, we found little for web application developers interested in protecting their users’ privacy; so, we want to document what we’ve learned in hope of making these techniques more common, and developing better critiques and improvements of the approaches we’ve taken so far. Below, we outline four techniques we use at Wesabe which we think any web application developer should consider using themselves, and describe the benefits and drawbacks to each.
Keep Critical Data Local
As a web application developer, the best way to ensure that you protect the privacy of a user’s data is not to have that data at all. Of course, it’s hard to develop a useful application without any data, but it is worth asking, is there any information you don’t absolutely need, which you could make sure not to have at all?
In designing Wesabe, we decided that the most sensitive information in our system would be the bank and credit card website usernames and passwords for our users. These credentials uniquely identify a person to the site, allow them to make security-critical actions such as bill payments and bank transfers, and enable access to other information, such as account numbers, that can be used for identity theft. In interviewing people about the Wesabe idea, we heard loud and clear that consumers were, quite rightly, extremely sensitive about their bank passwords, having been inundated by news reports and bank warnings about phishing.
Our solution was to make sure our users did not have to give us their bank and credit card credentials. Instead, we provide an optional, downloadable application, the Wesabe Uploader, which keeps their credentials on their own computer. The Uploader contacts the bank and credit card sites directly, and uses the user’s credentials to log in and download their data. It then strips sensitive information out of the data file (such as the user’s account number), and uploads just the transaction data to Wesabe. The Uploader acts as a privacy agent for the user. (We also provide a way for the user to manually upload a data file they’ve downloaded from their bank or credit card web site, though this requires more effort on their part.)

The advantages of the client model are that the user need not invest as much trust in the web application as they would otherwise, and that we do not have a central database of thousands of users’ bank credentials (a very tempting target for an attacker). As a small startup, not having to ask our users for as much trust is great — we can grow without needing people to be willing to give us their bank credentials from the start. Likewise, as a user of the site, you can try it out without having to surrender these credentials just to experiment. The Uploader approach has been extremely successful for us — our users have (as of early April 2007) uploaded nearly half a billion dollars in transaction data, with over 80% of that information coming through the Uploader.
The most significant disadvantage of the Uploader model is that it places a significant security burden on the user. If the user’s machine is vulnerable, storing bank passwords on their machine does not protect them. (Note, however, that if the user’s machine is vulnerable, an attacker can go after those same credentials via the web browser, so in some sense the burden on the user is the same.) Asking a user to download a client application is also a usability burden, since it requires greater commitment and trust that the client application does what it says it does and does not contain spyware or trojans. Finally, if we were to become very successful, the Uploader application could itself become a specific target for trojans, degrading its benefit.
Overall, we believe that a local client is a good privacy tool for new companies, and for applications where some data should absolutely never be placed on a server. Wesabe will continue to provide a local client for all users, but we will also move to providing other data syncing tools that do not require a client download, since we believe that over time people will be more comfortable with those approaches and will want the convenience of not running the Uploader. For now, though, a local client has been a great approach for us, and should be considered whenever an application involves data the user legitimately would hesitate to ever upload.
Use a Privacy Wall to Separate Public and Private Data
The first people we asked to upload data to Wesabe were some of our closest friends. Many of them replied, “Um, will you be able to see all my bank data, then?” Even people who trusted us were, understandably, very reluctant to participate. We devised a method, the “privacy wall,” for protecting their information even from us as developers of the site. We believe this model is a good approach to ensuring that employees of a company have the least possible access to users’ data, and to minimizing the harm that would come from a security breach on the site.
The idea of a privacy wall is simple: don’t have any direct links in your database between your users’ “public” data and their private data. Instead of linking tables directly via a foreign key, use a cryptographic hash that is based on at least one piece of data that only the user knows-such as their password. The user’s private data can be looked up when the user logs in, but otherwise it is completely anonymous. Let’s go through a simple example.
Let’s say we’re designing an application that lets members keep a list of their deepest, darkest secrets. We need a database with at least two tables: ‘users’ and ‘secrets’. The first pass database model looks like this:
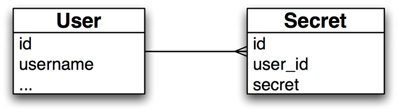
The problem with this schema is that anyone with access to the database can easily find out all the secrets of a given user. With one small change, however, we can make this extremely difficult, if not impossible:
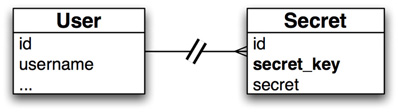
The special sauce is the ‘secret_key’, which is nothing more than a cryptographic hash of the user’s username and their password (plus a salt). When the user logs in, we can generate the hash and store it in the session. Whenever we need to query the user’s secrets, we use that key to look them up instead of the user id. Now, if some attacker gets ahold of
the database, they will still be able to read everyone’s secrets, but they won’t know which secret belongs to which user, and there’s no way to look up the secrets of a given user.
So what you do if the user forgets their password? The recovery method we came up with was to store a copy of their secret key, encrypted with the answers to their security questions (which aren’t stored anywhere in our database, of course). Assuming that the user hasn’t forgotten those as well, you can easily find their account data and “move it over” when they reset their password (don’t forget to update the encrypted secret key); if they do forget them, well, there’s a problem.
The privacy wall technique has a number of possible weaknesses. As mentioned earlier, we store the secret key in the user’s session. If you’re storing your session data in the database and your database is hacked, any users that are logged in (or whose sessions haven’t yet be deleted) can be compromised. The same is true if sessions are stored on the filesystem. Keeping session data in memory is better, although it is still hackable (the swapfile is one obvious target). However you’re storing your session data, keeping your sessions reasonably short and deleting them when they expire is wise. You could also store the secret key separately in a cookie on the user’s computer, although then you’d better make damn sure you don’t have any cross-site scripting (XSS) vulnerabilities that would allow a hacker to harvest your user’s cookies.
Other holes can be found if your system is sufficiently complex and an attacker can find a path from User to Secret through other tables in the database, so it’s important to trace out those paths and make sure that the secret key is used somewhere in each chain.
A harder problem to solve is when the secrets themselves may contain enough information to identify the user, and with the above scheme, if one secret is traced back to a user, all of that user’s secrets are compromised. It might not be possible or practical to scrub or encrypt the data, but you can limit the damage of a secret being compromised. We later came up with the following as an extra layer of security: add a counter to the data being hashed to generate the secret key:
secret key 1 = Hash(salt + password + ‘1’) secret key 2 = Hash(salt + password + ‘2’) … secret key n = Hash(salt + password + ‘
Getting a list of all the secrets for a given user when they log in is going to be a lot less efficient, of course; you have to keep generating hashes and doing queries until no secret with that hash is found, and deleting secrets may require special handling. But it may be a small price to pay for the extra privacy.
Data Fuzzing and Log Scrubbing
While this is the most basic and best-known of the techniques we describe, it’s also probably the most important. Application developers naturally want to keep as much information about the operation of the application as possible, in order to properly debug problems. They also want to have that information be as accurate as possible, so that disparate events can be correlated easily. Unfortunately, both of those desires often fly right in the face of protecting your users’ privacy. Techniques such as the Privacy Wall are pretty much useless if your log files allow someone to pinpoint exact information about a user’s actions. To prevent logs and other records from violating users’ privacy, those records should purposefully omit or obscure information that would uniquely identify a user or a user’s data.
Early in the development of Wesabe, we hit this problem when one of the developers found an exception on our login page. Since exceptions are reported into our bug system and also emailed to all of the developers, the exception sent around a full record of the action, *including* the developer’s login password (since that was one of the POST parameters to the request that failed). After that developer changed his password, we went about making sure that any sensitive information would not be logged in exception reports. Good thing, too — the next day, one of our early testers hit another login bug, and her action caused an exception report, fortunately containing “‘password’=>'[FILTERED]'” rather than her real password. Setting up exception reports to omit a list of named parameters in exception reports is necessary precaution to prevent errors from causing privacy leaks. (In Ruby on Rails, which we use at Wesabe, there is a filter_parameter_logging class method in ActionController::Base that exists for just this purpose.)
Another good datum to filter is IP address. Of course tracking IP addresses is useful for security auditing and reporting on usage for an application. However, there is usually no need for every log in the application to record the full IP address at every point. We recommend zeroing-out that last two quads of the IP — changing 10.37.129.2 to 10.37.0.0 — whenever possible. Most of the time, this information is completely sufficient for application-level debugging, and prevents identifying a specific user on a network by correlating with other network logs. (Google recently announced their intention to mask the last quad of IP address information after 18-24 months, in order to better protect their users’ privacy and comply with EU privacy laws.)
Likewise, dropping precision on dates — or dropping dates altogether — can significantly protect a user. One of our advisors suggested this practice to us after an experience with an anonymous source inside a company, sending him email with information. He noticed that date information, which is often logged with date and hour/minute/second precision, could uniquely identify a sender even if no other information is present. Obviously some logs will need date information to be useful for debugging, but if possible, dropping whatever precision you can from a date log is good protection.
For our application, tracking personal finances, a similar approach could be taken with transaction amounts. A record of all financial transactions, with payee, date, and amount, could be used to identify a particular person even without any additional information. By rounding dollar amounts to the nearest dollar, or randomly selecting a cents amount for each transaction, the application would allow a user to have a good-enough estimate of their spending without penny-level precision. (The privacy threat here would be a request for “all transactions at Amazon on May 13th for $23.45” — a fairly limited result set, especially since not all Amazon buyers are Wesabe users.)
With all of these filters, you lose a certain amount of precision in your ability to debug a problem when one does occur. One workaround for this is to retain precision and sensitive data where needed, but to write that data to a separate, well-secured file store, and to send a reference to the captured data to the developers. In this way, needed information is
centralized and protected under stricter policies, while the email broadcast or bug report announcing the problem is sanitized.
All of these techniques are beneficial when faced with accidental privacy leaks or a desire to avoid having data that would make your service a target of forced data recovery (either criminal, such as a coordinated attack, or governmental, such as a subpoena). However, covering all of the types of data mentioned above in all parts of your application is difficult, and requires care from all developers on the project. Likewise, none of these techniques would prevent a trace and tap (wiretap) order from mandating a change to the application specifically to target a user. Nonetheless, we believe all of the filters mentioned above are both good practice and substantial privacy protections.
Use Voting Algorithms to Determine Public Information
One of the purposes of Wesabe is to aggregate our users’ transaction histories around merchants. This allows us to provide pricing information (what is the average price for this plumber’s services?) and other useful data (if all the Wesabe members who try this restaurant never go back, it’s probably not very good). We faced a problem, though, in developing this feature — how should we determine which payees are really “merchants” for which we should aggregate and publish data, versus private transactions (such as a check from a wife to her husband), which we definitely should not publish? We decided to use a voting algorithm to help sort this out.

The idea for using a voting algorithm came from an interesting online application called the “ESP Game” (see www.espgame.org). The purpose of the ESP Game was to improve image search engines by getting two people to
collaborate on labeling a random image from the web. People who register with the site may start a labeling game at any time, and they are randomly matched based on when the request a game. Presumably, the two participants do not know each other and have no way of communicating except through the game. They are both shown an image at the same time, and asked to enter words that describe the image. If they both enter the same word, they get points in the game and are shown another image (and so on, until a timer runs out). This approach helps improve image searching since two people are agreeing on one term that describes the image, and that image can then be returned for searches on that term. The image is described by people who understand it, rather than having to be analyzed by a computational process that can extract very limited information from it.
Wesabe uses the same approach to determine when we should start publishing aggregate information about a merchant. We wait until a “quorum” of users has identified a transaction as being at a particular merchant name before publishing any information about that merchant. As an example, say that User A downloads their transactions from their bank and uploads them to Wesabe. Each transaction has a description of the payee provided by the bank. These descriptions are often quite obscure, such as:
DEB/14673 SAFEWA 37 19 OAKLS G
User A can then edit the payee to a form they’ll more easily recognize, such as:
Safeway
This benefits User A, since their subsequent transactions at Safeway will be automatically converted for them. User B then uploads their own data, and edits one of their transactions to the payee name “Safeway,” too. This repeats for Users C, D, E, and so on. When a certain threshold of users have all used the same merchant name to describe one of their transactions, we aggregate the transactions with that payee name and release a page on “Safeway” that contains the data we’ve collected.
This approach offers several benefits. First, this method works on completely opaque information — ESP Game does not need image analysis algorithms, and we do not need a battery of regular expressions to comprehend the bank’s payee representation. Second, we are essentially defining a merchant based on the amount of transaction activity in which that merchant participates. This allows us to capture a far broader range of merchant information — for instance, eBay and Craig’s List sellers — than would be available if we simply bought a database of merchant names. Third, users do not need to manually identify each transaction as public or private — we simply draw the line based on a consensus among our users that a merchant should be public. Finally, no developer or Wesabe employee needs to make the public/private distinction, either (that is, the system is fully automated). When people agree on a merchant name, that name is common knowledge; if enough people agree, it is probably public knowledge.
There are a few drawbacks, of course. We understate the full extent of our database in our public pages, simply because some real merchants have not yet reached a quorum and thus are not published in our index. Likewise, a private individual who collects checks from many Wesabean friends for a group activity may find themselves listed in our index when they should not be. That said, we believe the automation and scope benefits outweigh these drawbacks.
More Information
While we’ve written above about software techniques for protecting users’ privacy, there are also policy techniques for the same ends. We have published a Data Bill of Rights to specify the promises we make to our users about the treatment of their data, which any organization is free to copy.